Bullhorn Batch Ingestion Part 1: 3-Legged OAuth and Rotating Refresh Tokens
Bullhorn's API uses 3-legged OAuth, built for human-in-the-loop apps. Building a backend batch sync on top meant designing around that mismatch, plus the rotating refresh tokens Bullhorn issues and the failure modes that come with them.

Hi! This is the first post in a three-part series I’m writing. The system I built is a scheduled batch job that pulls data from Bullhorn and writes it to S3 as Iceberg tables. Downstream, those tables serve internal dashboards through Athena and AI-driven analytics through Snowflake.
Bullhorn is a CRM for staffing and recruiting companies. Think Salesforce, but purpose-built around the recruiting workflow (candidates, jobs, submissions, placements, prescreen notes).
This post is about Bullhorn’s custom OAuth 2.0 flow and the edge cases it brings to a backend batch sync.
Part 2 will cover the incremental sync logic itself and the associated nuances of working with both JPQL-based queries and Lucene-backed indexing.
And Part 3 covers pipeline engineering: storage decisions + tradeoffs, downstream use cases, and how I designed the sync for its consumers.
Bullhorn’s REST API reference is here if you want to follow along.
3-Legged vs. 2-Legged OAuth: Why It Matters for a Batch Pipeline
The first interesting design constraint when building a Bullhorn batch pipeline is that Bullhorn’s API uses 3-legged OAuth.
3-legged OAuth is designed to account for a “user in the loop” who explicitly authorizes access to resources. It’s the type of pattern you see when an app acts on behalf of a user. For example, signing in with Google on an external site, where Google shows an explicit consent screen before granting the external app permission.
Bullhorn holds user-owned data (a recruiter’s contacts, pipeline, calendar), so anchoring every API session to a specific user identity is a logical default.
The three “legs” in 3-legged OAuth are:
- The user (resource owner of the data that will be accessed)
- The client app (the thing you’re building)
- The authorization server/API (Google, LinkedIn, Bullhorn etc.) that owns the data
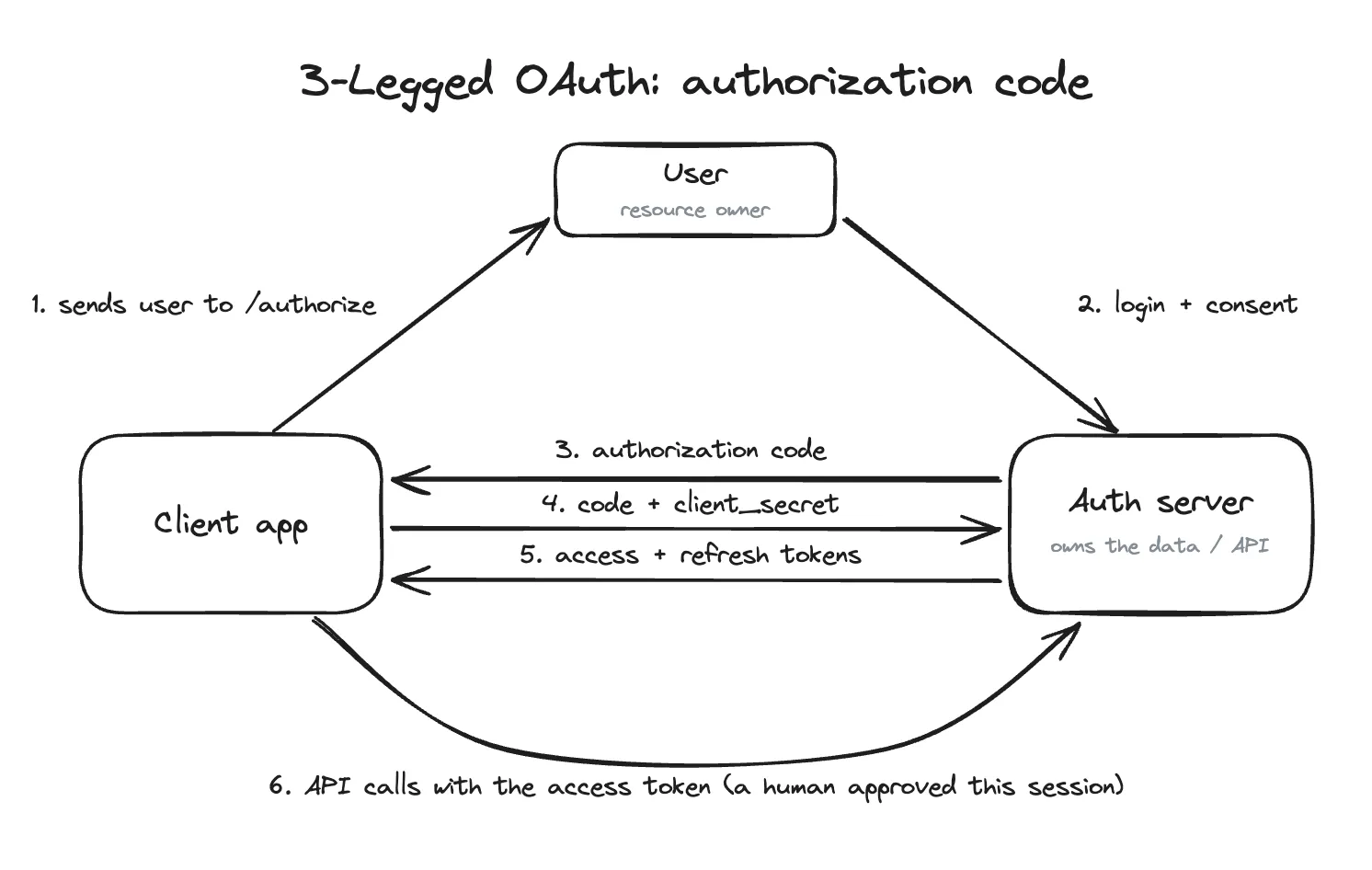
3-legged OAuth: a human approves the session before any tokens are issued (typical 3LO flow).
In contrast, 2-legged OAuth has only the last two: the client app and the auth server (there’s no user). The client app presents its own credentials (client ID and secret) to get an access token, then uses that token to call the API.
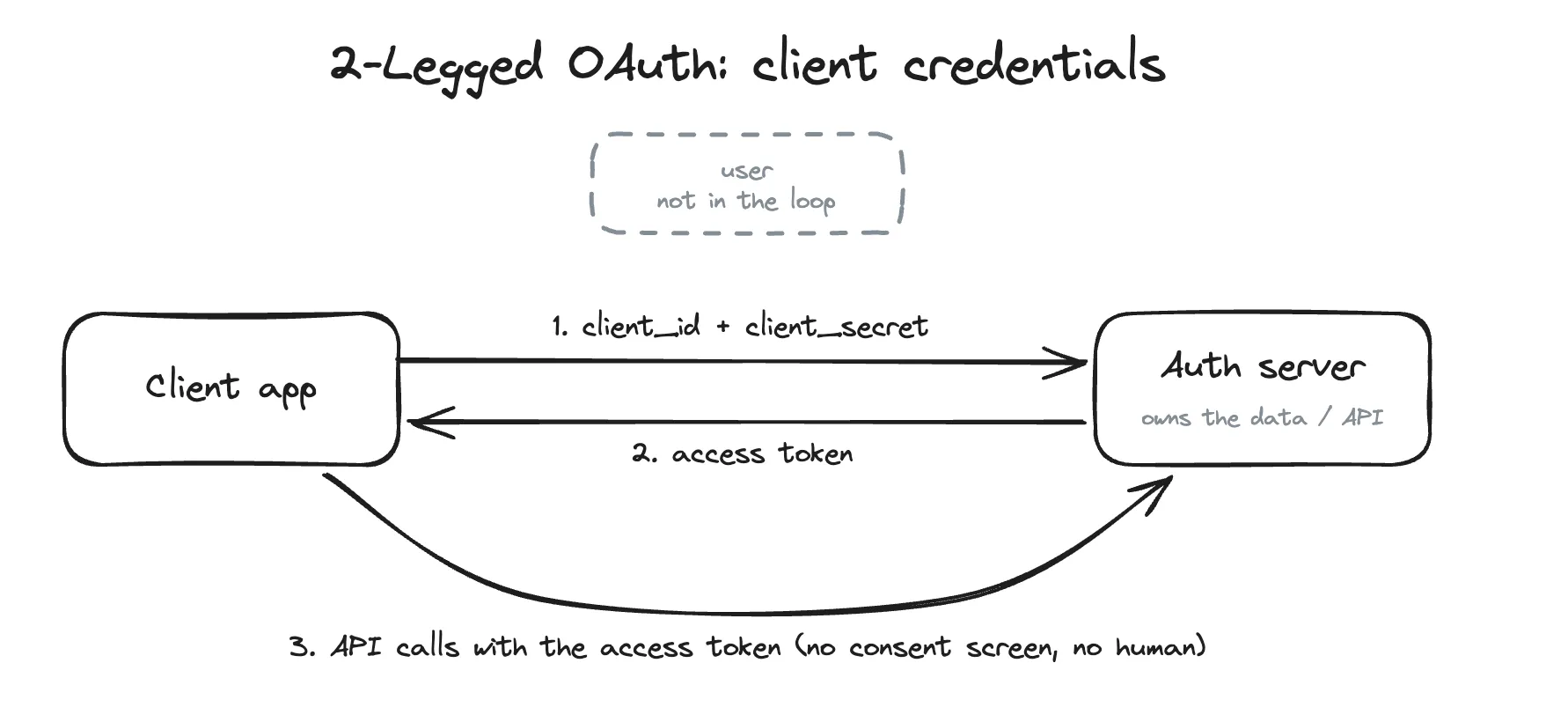
2-legged OAuth: the client authenticates as itself. No user, no consent screen (typical 2LO flow).
2-legged OAuth (2LO) is a server-to-server pattern, and fits an ingestion pipeline more natively than 3-legged OAuth (3LO) does.
Many CRMs are built around 3LO, but some (Salesforce for example) also offer the OAuth 2.0 client credentials flow for backend integrations. Bullhorn doesn’t offer this, however.
Much of the pipeline’s complexity came from this mismatch: a server-to-server batch job (typically 2LO territory) running on a 3LO flow. Without a client-credentials grant, the thing that keeps the integration alive between runs is a single-use refresh token. And storing, rotating, and recovering that token becomes the pipeline’s problem.
Bullhorn’s Auth Flow and The Refresh Token Problem
Before we discuss some of these complexities, it’s important to understand what Bullhorn’s specific auth flow looks like.
Bullhorn’s auth flow steps:
- Look up your data center URLs. Call GET
/rest-services/loginInfowith your username. - Get an authorization code. Call GET
/oauth/authorizewithclient_id,response_type=code, username, password, andaction=Login. The code comes back on the redirect URL. - Exchange the code for tokens. Call POST
/oauth/tokenwithgrant_type=authorization_code, the code,client_id, andclient_secret. You get back a short-lived access token (10 minutes) and a long-lived refresh token. - Exchange the access token for a session. Call POST
/rest-services/login?version=*&access_token=...to get aBhRestTokenand therestUrlyour API calls will hit. - Make API calls. Use the
BhRestTokenandrestUrlon every subsequent request until the session expires. - When the session expires, either go through the login flow from step 2 again, or use the existing refresh token to receive a new access token (+ a new refresh token), which you can then exchange for a new
BhRestToken.
Note that this flow differs slightly from the standard 3LO pattern (in the previously shown diagram) because the access token never touches the API. It’s spent once at /login to grant a BhRestToken which is what you use to make API calls.
The interesting architectural question arises in step 6 — what we do when the session expires. Sessions are capped server-side at 48 hours, and Bullhorn’s docs warn: “Never assume that a REST session will not expire”.
There are two renewal paths:
- Re-run the full auth flow (avoid the refresh token). This was what I did in my first version of the pipeline. When the session expires, you pass username, password, and
action=Loginto/authorizeand start the auth process over. This is simple and you can keep service-account credentials stored as a secret in something like AWS Secrets Manager. The tradeoff, however, is that Bullhorn throttles login rates. And depending on the frequency of your sync, you could get blocked. - Use the refresh token. This dodges the login throttling, but Bullhorn’s refresh tokens are single-use: “a refresh token expires after it is used once”, so the old token is dead the instant the new one is issued. That creates a gap between receiving the new token and persisting it. If a network error eats the response, or the write to storage fails, the new token is lost and the old one is already retired. The next run would load a dead token, and the sync is stuck. Concurrency guards can serialize scheduled runs, but they don’t cover every situation where there could be a concurrent sync (e.g. a manual backfill). And a run executing alone could hold a stale read, writing back a token that’s already been rotated.
As aforementioned, I built around option 1 at first — avoiding refresh tokens entirely. But as the pipeline developed, I needed to prevent the possibility of being blocked by Bullhorn’s login throttling. This created an obligation to build out a refresh token handling process.
Refresh Token Error Handling: DynamoDB and invalid_grant Fallback
The design for handling refresh token errors has both a prevention layer and a recovery layer.
Prevention: a state store with a lease and conditional writes. The prevention layer is two guards on one DynamoDB row, both of which follow a compare-and-swap pattern. The refresh token changes on every use (mutable), so we store the auth state like this:
pk: "auth#token"
{ refresh_token, bh_rest_token, rest_url,
oauth_url, login_url,
session_expires_at, version }Guard 1 happens before calling Bullhorn’s refresh endpoint. When a run sees the session_expires_at value is about to hit, it tries to take a lease on the auth#token row by writing a refresh_lease_until timestamp. But that write will only occur if the row’s version is the same as when it initially read; and there cannot be a live lease (either the lease field is missing or has expired):
self._table.update_item(
Key={"pk": "auth#token"},
UpdateExpression=(
"SET refresh_lease_until = :lease"
),
# only if nobody rotated since my read
# and no live lease is held
ConditionExpression=(
"version = :v AND "
"(attribute_not_exists(refresh_lease_until)"
" OR refresh_lease_until < :now)"
),
...
)So, if the run’s write fails, that means someone has already rotated the token (+ bumped the version), or a run is mid-rotation. In that case, the run adopts the new state once the rotation completes. If a lease-holding run crashes, the lease will eventually expire on its own.
Guard 2 happens when a refresh has succeeded. At this moment, the run that did the refresh holds the only active refresh token and the old one is permanently dead. So, I implemented a conditional write-back that only saves the new token if the row’s version is the same version that was seen at the run’s read-time. If the version is the same, it writes the new refresh token, bumps the version + 1, and removes the lease:
self._table.put_item(
Item={
"pk": "auth#token",
# the new, unspent token
"refresh_token": token.refresh_token,
...
"version": expected_version + 1,
},
# row unchanged since my read
ConditionExpression="version = :v",
...
)If the condition failed, it means another run managed to rotate and save a newer token first (so this run is stale). In this case, the run re-reads the row and version and adopts the new state. This prevents stale runs from overwriting the current refresh token with a dead one.
Recovery: an invalid_grant fallback to /authorize. If a network error occurs on Bullhorn’s end, or our app fails to persist the new refresh token, the next run loads a dead token and gets invalid_grant. The pipeline re-reads the state row and asks if the stored token is still the one that just failed. If a newer token is there, another run already rotated it. So we adopt that session. If it’s the same dead token, the pipeline bootstraps the full /authorize flow with the stored log-in credentials (under the same lease, so two failing runs can’t both burn a login). This allows the sync to continue even if refresh token handling fails — and triggers a CloudWatch alarm to investigate.
TLDR: The refresh token lives as a single versioned row in DynamoDB. A lease ensures only one refresh is in flight across every client of the token, and a conditional write stops stale runs from overwriting newer state with a dead token. On invalid_grant, the pipeline first checks whether another run already rotated the token. If so, it adopts that session; if not, it falls back to the full /authorize flow (under the same lease, so two failing runs can’t both burn a throttled login) and fires a CloudWatch alarm to investigate.
Takeaways
Bullhorn’s 3LO flow takes extra care to design a reliable server-to-server sync. Complexity came from designing around persistence, failure recovery, and the operational edge cases. OAuth 2.0 is a wide protocol and it’s important to treat each provider’s implementation as its own system, with its own logic and failure modes.
Thanks for reading! In Part 2, I’ll dig deeper into several of Bullhorn’s API query engines and their interesting quirks — where JPQL-based queries and Lucene-backed indexing disagree, and what that means for ordering and pagination.